
大数据 文件系统,大数据时代下的文件系统架构与优化策略
时间:2025-01-08 来源:网络 人气:
你有没有想过,那些庞大的数据是如何被妥善保管和高效处理的呢?今天,就让我带你走进大数据的世界,揭开文件系统的神秘面纱。
大数据的守护者:HDFS的诞生
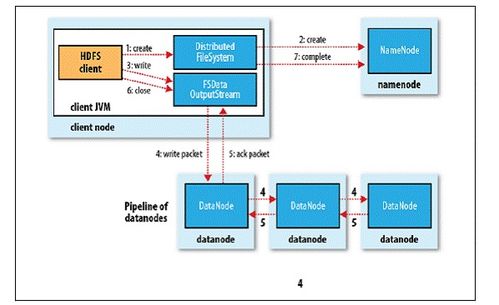
想象你手中拿着一张巨大的拼图,而拼图的每一块都散落在不同的地方。这时,你需要一个系统来帮助你整理、存储和快速找到这些碎片。Hadoop分布式文件系统(HDFS)就是这样一款神奇的工具。
HDFS的灵感来源于Google文件系统(GFS),由Apache软件基金会的Hadoop项目团队开发。2006年,Doug Cutting和Mike Cafarella基于Google的GFS论文,开始开发HDFS,成为Hadoop框架的基础组件之一。
HDFS的魔法:高容错性
HDFS的魔法之一就是它的容错性。它将数据切分成多个块(通常是128MB或256MB),并将这些块副本存储在多个不同的节点上。这样一来,即使某些节点故障,数据依然可以从其他副本中恢复,就像拼图中的碎片即使丢失了一块,也能通过其他碎片找到完整的图案。
HDFS的魔法:高吞吐量
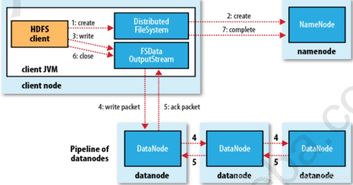
HDFS的另一个魔法是它的高吞吐量。它通过批量处理大数据,优化了数据的读写速度。想象你正在用一把大勺子舀水,而不是用小杯子,这样效率是不是高多了?
HDFS的魔法:可扩展性
HDFS的可扩展性就像一个不断成长的魔法森林,你可以随时添加新的树木(节点),让森林变得更茂盛。这样一来,无论你的数据量有多大,HDFS都能轻松应对。
HDFS的魔法:简化数据一致性模型
HDFS采用写一次、读多次的语义模型,简化了数据一致性的管理。这意味着,你只需要关注数据的写入,而不用担心数据的一致性问题,就像你只需要关注拼图的最后一块,而不用担心其他碎片的位置。
HDFS的魔法:支持数据本地性
HDFS优先在存储数据的节点上处理计算任务,从而减少网络传输,提高处理效率。想象你正在和一个朋友聊天,而你们都在同一个房间,这样交流是不是更方便?
HDFS的魔法:HDFS集群
HDFS集群由NameNode(主节点)、SecondaryNameNode(辅助节点)、DataNode(从节点)构成。NameNode负责管理整个HDFS集群,SecondaryNameNode辅助NameNode管理元数据,DataNode负责存储实际的数据块(一个block块默认大小128MB)和对数据块的读、写操作。
HDFS的魔法:HDFS的架构
HDFS的架构主要包括两个重要组件:HDFS的主服务器和HDFS的从服务器。
- HDFS的主服务器负责管理文件系统的命名空间和客户端对文件访问,保存文件具体信息(文件信息、文件拆分block块信息、以及block和DataNode的信息),接收用户请求,保存具体的block数据。
- HDFS的从服务器负责数据的读写操作和复制操作,向NameNode报告当前存储或者修改的数据信息,DataNode之间进行相互通信,复制数据块,定时与NameNode进行同步(合并fsimage和edits)。
HDFS的魔法:HDFS的应用场景
HDFS的应用场景非常广泛,包括但不限于:
- 大数据存储:HDFS可以存储海量数据,适用于各种大数据应用场景。
- 数据分析:HDFS可以快速读取和写入数据,适用于大数据分析。
- 机器学习:HDFS可以存储大量的训练数据,适用于机器学习。
在这个大数据时代,HDFS就像一位魔法师,用它的魔法守护着我们的数据,让我们的数据变得更加安全、高效和可靠。让我们一起走进HDFS的世界,感受大数据的魅力吧!
相关推荐
教程资讯
教程资讯排行









