
(asr)系统,语音识别技术的核心应用
时间:2024-10-17 来源:网络 人气:
ASR系统:语音识别技术的核心应用

ASR系统的基本原理
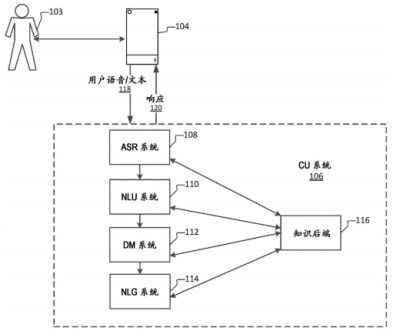
ASR系统是指将人类的语音信号转换为计算机可以理解和处理的文本信息的技术。其基本原理主要包括以下几个步骤:
语音信号采集:通过麦克风等设备采集语音信号。
预处理:对采集到的语音信号进行降噪、去噪等处理,提高信号质量。
特征提取:将预处理后的语音信号转换为计算机可以处理的特征向量。
模型训练:使用大量标注好的语音数据对模型进行训练,使其能够识别不同的语音。
语音识别:将特征向量输入到训练好的模型中,得到识别结果。
ASR系统的应用领域
智能语音助手:如苹果的Siri、亚马逊的Alexa等,为用户提供便捷的语音交互体验。
语音翻译:如谷歌翻译、百度翻译等,实现不同语言之间的实时翻译。
语音识别软件:如讯飞语音、科大讯飞等,为用户提供语音输入、语音搜索等功能。
车载语音系统:如特斯拉、比亚迪等,实现车载系统的语音控制。
智能家居:如小米、华为等,实现智能家居设备的语音控制。
ASR系统的挑战与发展趋势

尽管ASR技术取得了显著的成果,但仍面临一些挑战:
语音识别准确率:在复杂环境、多语种、方言等情况下,语音识别准确率仍有待提高。
实时性:在实时语音交互场景中,如何保证语音识别的实时性是一个重要问题。
隐私保护:在语音识别过程中,如何保护用户的隐私是一个亟待解决的问题。
深度学习:深度学习技术在ASR领域的应用越来越广泛,有望进一步提高语音识别准确率。
多模态融合:将语音、图像、文本等多种模态信息进行融合,提高语音识别的鲁棒性和准确性。
个性化定制:根据用户的需求和习惯,为用户提供个性化的语音识别服务。
ASR系统作为语音识别技术的核心应用,在人工智能领域具有广泛的应用前景。随着技术的不断发展和创新,ASR系统将在未来为人们的生活带来更多便利和惊喜。
作者 小编
相关推荐
教程资讯
教程资讯排行









